HADOOP چیست؟
Apache Hadoop یک چارچوب متن باز است که برای ذخیره و پردازش کارآمد مجموعه داده های بزرگ در اندازه های مختلف از گیگابایت تا پتابایت داده استفاده می شود. به جای استفاده از یک کامپیوتر بزرگ برای ذخیره و پردازش داده ها، Hadoop اجازه می دهد تا چندین کامپیوتر را خوشه بندی کند تا مجموعه داده های عظیم را به صورت موازی سریعتر تجزیه و تحلیل کند؛ که این امر در سرو اچ پی و فروش سرور HP نیز صدق می کند.
Hadoop از چهار ماژول اصلی تشکیل شده است:
- 1. سیستم فایل توزیع شده Hadoop (HDFS) - یک سیستم فایل توزیع شده که بر روی سخت افزار استاندارد یا پایین رده اجرا می شود. HDFS علاوه بر تحمل خطا بالا و پشتیبانی بومی از مجموعه داده های بزرگ، خروجی داده بهتری را نسبت به سیستم های فایل سنتی ارائه می دهد.
- 2. مذاکره کننده دیگری برای منابع (YARN) گره های خوشه ای و استفاده از منابع را مدیریت و نظارت می کند. کارها و وظایف را برنامه ریزی می کند.
- 3. MapReduce - چارچوبی که به برنامه ها کمک می کند تا محاسبات موازی روی داده ها را انجام دهند. وظیفه نقشه داده های ورودی را می گیرد و آن را به مجموعه داده ای تبدیل می کند که می تواند در جفت مقادیر کلیدی محاسبه شود. خروجی کار نقشه با کاهش کارها مصرف می شود تا خروجی را جمع کرده و نتیجه مطلوب را ارائه دهد.
- 4. Hadoop Common - کتابخانه های رایج جاوا را ارائه می دهد که می توانند در همه ماژول ها استفاده شوند.
HADOOP چگونه کار میکند
Hadoop استفاده از تمام ظرفیت ذخیره سازی و پردازش در سرورهای خوشه ای در فروش سرور HP و اجرای فرآیندهای توزیع شده در برابر حجم عظیمی از داده ها را آسان تر می کند. Hadoop بلوک های ساختمانی را فراهم می کند که سایر خدمات و برنامه ها را می توان بر اساس آنها ساخت.
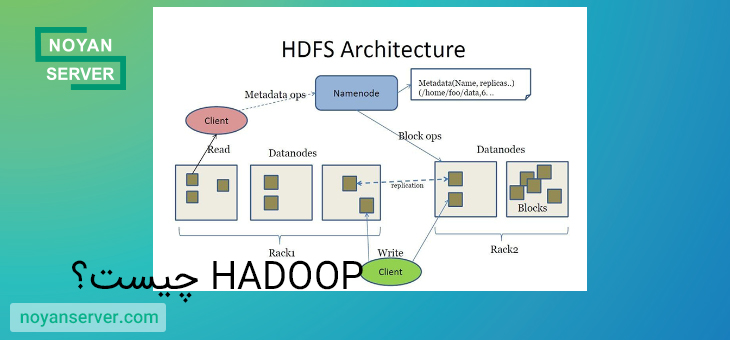
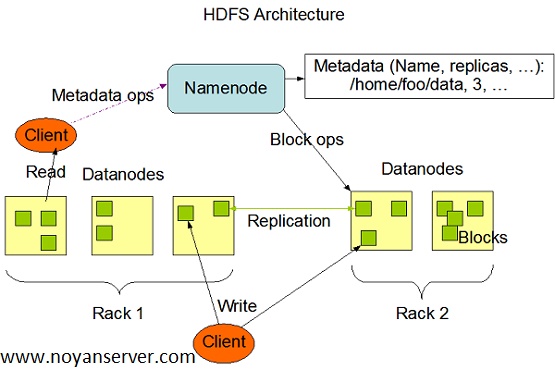
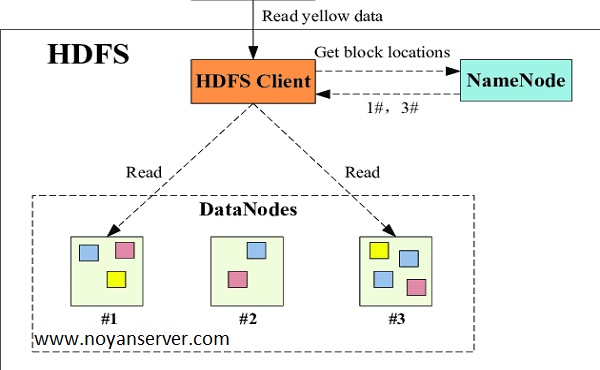
برنامههایی که دادهها را در قالبهای مختلف جمعآوری میکنند، میتوانند با استفاده از یک عملیات API برای اتصال به NameNode، دادهها را در خوشه Hadoop قرار دهند. NameNode ساختار دایرکتوری فایل و قرار دادن «تکهها» را برای هر فایل، که در DataNodes تکرار میشود، ردیابی میکند. برای اجرای یک کار برای پرس و جو از داده ها، یک کار MapReduce که از نقشه های زیادی تشکیل شده است ارائه دهید و وظایفی را که در برابر داده های HDFS در سراسر DataNodes اجرا می شوند، کاهش دهید. وظایف نقشه بر روی هر گره در برابر فایل های ورودی ارائه شده اجرا می شوند و کاهش دهنده ها برای جمع آوری و سازماندهی خروجی نهایی اجرا می شوند.
اکوسیستم هادوپ در طول سال ها به دلیل توسعه پذیری رشد قابل توجهی داشته است. امروزه اکوسیستم Hadoop شامل ابزارها و برنامه های کاربردی بسیاری برای کمک به جمع آوری، ذخیره، پردازش، تجزیه و تحلیل و مدیریت کلان داده ها است؛ همچنین در سرورها و فروش سرور HP کاربرد دارد.
برخی از محبوب ترین برنامه ها عبارتند از:
- Spark - یک سیستم پردازشی منبع باز و توزیع شده که معمولاً برای حجم کاری داده های بزرگ استفاده می شود. Apache Spark از کش در حافظه و اجرای بهینه برای عملکرد سریع استفاده میکند و از پردازش دستهای عمومی، تجزیه و تحلیل جریان، یادگیری ماشین، پایگاههای داده گراف و پرس و جوهای موقت پشتیبانی میکند.
- Presto - یک موتور پرس و جوی SQL توزیع شده منبع باز و بهینه شده برای تجزیه و تحلیل موقت و کم تاخیر داده ها. این استاندارد ANSI SQL را پشتیبانی می کند، از جمله پرس و جوهای پیچیده، تجمیع، اتصالات و توابع پنجره. Presto می تواند داده ها را از چندین منبع داده از جمله سیستم فایل توزیع شده Hadoop (HDFS) و Amazon S3 پردازش کند.
- Hive – به کاربران این امکان را می دهد که از Hadoop MapReduce با استفاده از یک رابط SQL استفاده کنند و تجزیه و تحلیل را در مقیاس وسیع و علاوه بر ذخیره سازی داده های توزیع شده و مقاوم در برابر خطا امکان پذیر می کند؛ حتی بروی فروش سرور HP نیز تاثیر گذار است.
- HBase – یک پایگاه داده متن باز، غیر رابطه ای و نسخه شده که در بالای Amazon S3 (با استفاده از EMRFS) یا سیستم فایل توزیع شده Hadoop (HDFS) اجرا می شود. HBase یک فروشگاه داده بزرگ توزیع شده و مقیاسپذیر است که برای دسترسی تصادفی، کاملاً سازگار و در زمان واقعی برای جداول با میلیاردها ردیف و میلیونها ستون ساخته شده است.
- Zeppelin - یک نوت بوک تعاملی که امکان کاوش تعاملی داده ها را فراهم می کند.
اجرای Hadoop در AWS
Amazon EMR یک سرویس مدیریت شده است که به شما امکان می دهد مجموعه داده های بزرگ را با استفاده از آخرین نسخه های چارچوب های پردازش کلان داده مانند Apache Hadoop، Spark، HBase و Presto در خوشه های کاملاً قابل تنظیم پردازش و تجزیه و تحلیل کنید.
- استفاده آسان: می توانید یک خوشه آمازون EMR را در عرض چند دقیقه راه اندازی کنید. شما نیازی به نگرانی در مورد تهیه گره، راه اندازی کلاستر، پیکربندی Hadoop یا تنظیم خوشه در سرور و فروش سرور HP ندارید.
- هزینه کم: قیمت گذاری آمازون EMR ساده و قابل پیش بینی است: برای هر ساعت نمونه ای که استفاده می کنید، نرخ ساعتی می پردازید و می توانید از Spot Instance ها برای صرفه جویی بیشتر استفاده کنید.
- الاستیک: با آمازون EMR، میتوانید یک، صدها یا هزاران نمونه را محاسبه کنید تا دادهها را در هر مقیاسی پردازش کنید.
- گذرا: میتوانید از EMRFS برای اجرای خوشههای درخواستی بر اساس دادههای HDFS که به طور مداوم در Amazon S3 ذخیره شدهاند، استفاده کنید. با پایان کار، می توانید یک خوشه را خاموش کنید و داده ها را در آمازون S3 ذخیره کنید. شما فقط برای زمان محاسبه ای که خوشه در حال اجرا است پرداخت می کنید.
- امن: آمازون EMR از تمام ویژگی های امنیتی مشترک سرویس های AWS استفاده می کند:
- نقش ها و سیاست های مدیریت هویت و دسترسی (IAM) برای مدیریت مجوزها.
- رمزگذاری در حین حمل و نقل و در حالت استراحت برای کمک به محافظت از داده های خود و رعایت استانداردهای مطابقت، مانند HIPAA.
- گروه های امنیتی برای کنترل ترافیک شبکه ورودی و خروجی به گره های خوشه ای شما.
- AWS CloudTrail: تمام تماسهای آمازون EMR PI که در حسابتان انجام میشود را بررسی کنید تا تجزیه و تحلیل امنیتی، ردیابی تغییر منابع و ممیزی انطباق را در سرور و فروش سرور HP ارائه دهید.
برای سوالات و راهنمایی ها بیشتر می توانید به صورت رایگان با کارشناسان ما در ارتباط باشید؛ همچنین شرکت بازرگانی نویان سرور ارائه دهنده خدمات پس از فروش من جلمه عیب یابی و تعمیرات سرور HP ، فروش قطعات سرور HP و گارانتی معتبر می باشد.